ANL 2024 Tutorial
Developing a negotiator
The agents for the ANL competition are standard NegMAS negotiators. As such, they can be developed using any approach used to develop negotiators in NegMAS.
To develop a negotiator, you need to inherit from the SAONegotiator class and implement the __call__() method.
Here is a simple random negotiator:
import random
from negmas.sao import SAONegotiator, SAOResponse
from negmas import Outcome, ResponseType
class MyRandomNegotiator(SAONegotiator):
def __call__(self, state):
offer = state.current_offer
if offer is not None and self.ufun.is_not_worse(offer, None) and random.random() < 0.25 :
return SAOResponse(ResponseType.ACCEPT_OFFER, offer)
return SAOResponse(ResponseType.REJECT_OFFER, self.nmi.random_outcomes(1)[0])
Testing the agent
from anl.anl2024 import anl2024_tournament
from anl.anl2024.negotiators import Boulware, Conceder, RVFitter
results = anl2024_tournament(
n_scenarios=1, n_repetitions=3, nologs=True, njobs=-1,
competitors=[MyRandomNegotiator, Boulware]
)
Will run 12 negotiations on 1 scenarios between 2 competitors
Output()
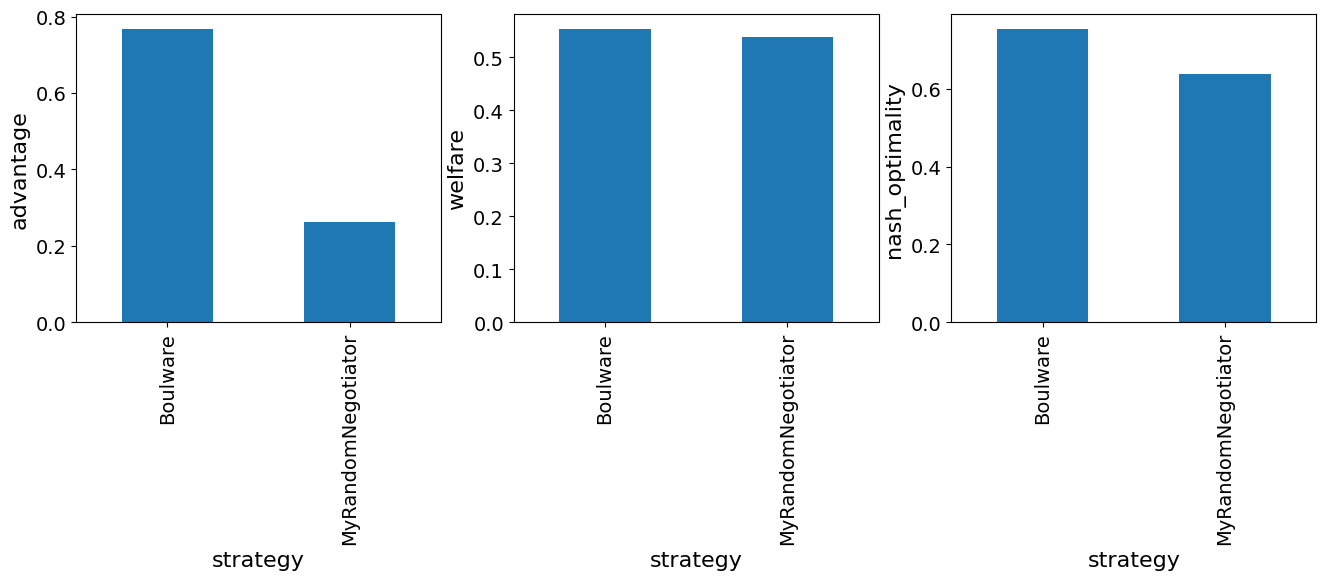
strategy score 0 Boulware 0.767437 1 MyRandomNegotiator 0.262742
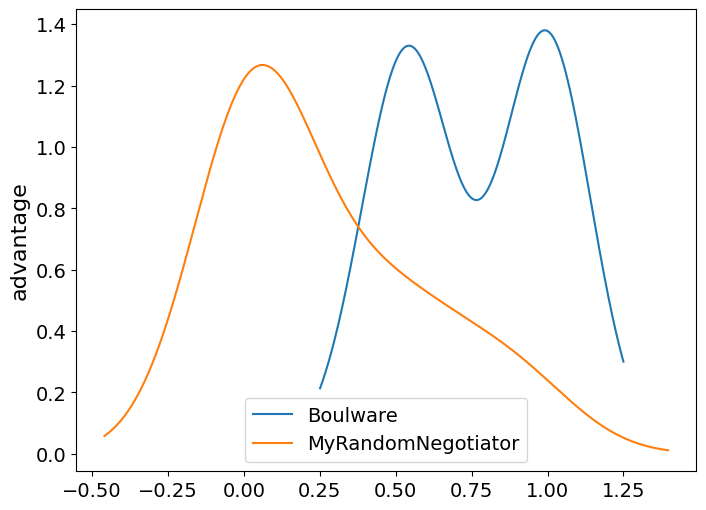
The score that is printed is the average advantage, which is the received utility minus the reservation value. We can immediately notice that MyRandomNegotiator is getting a negative average advantage which means that it sometimes gets agreements that are worse than disagreement (i.e. with utility less than its reservation value). Can you guess why is this happening? How can we resolve that?
You can easily check the final scores using the final_scores member of the returned SimpleTournamentResults object.
| strategy | score | |
|---|---|---|
| 0 | Boulware | 0.767437 |
| 1 | MyRandomNegotiator | 0.262742 |
The returned results are all pandas dataframes. We can use standard pandas functions to get deeper understanding of the results. Here is how to plot a KDE figure (kind of histogram) comparing different strategies in this tournament. The higher the line, the more often this value of the advantage is observed.
fig, ax = plt.subplots(figsize=(8,6))
df = results.scores
for label, data in df.groupby('strategy'):
data.advantage.plot(kind="kde", ax=ax, label=label)
plt.ylabel("advantage")
plt.legend();
fig, axs = plt.subplots(1, 3, figsize=(16,4))
for i, col in enumerate(["advantage", "welfare", "nash_optimality"]):
results.scores.groupby("strategy")[col].mean().sort_index().plot(kind="bar", ax=axs[i])
axs[i].set_ylabel(col)
Available helpers
Our negotiator was not so good but it exemplifies the simplest method for developing a negotiator in NegMAS. For more information refer to NegMAS Documentation. You develop your agent, as explained above, by implementing the __call__ method of your class.
This method, receives an SAOState which represents the current state of the negotiation. The most important members of this state object are current_offer which gives the current offer from the partner (or None if this is the beginning of the negotiation) and relative_time which gives the relative time of the negotiation ranging between 0 and 1.
It should return an SAOResponse represeting the agent's response which consists of two parts:
- A ResponseType with the following allowed values:
ResponseType.ACCEPT_OFFER, accepts the current offer (pass the current offer as the second member of the response).ResponseType.REJECT_OFFER, rejects the current offer (pass you counter-offer as the second member of the response).ResponseType.END_NEGOTIATION, ends the negotiation immediately (passNoneas the second member of the response).
- A counter offer (in case of rejection), the received offer (in case of acceptance) or
Noneif ending the negotiation.
The negotiator can use the following objects to help it implement its strategy:
self.nmiA SAONMI that gives you access to all the settings of this negotiation and provide some simple helpers:n_steps,time_limitThe number of rounds and seconds allowed for this negotiation (Nonemeans no limit).random_outcomes(n)Samplesnrandom outcomes from this negotiation.outcome_spaceThe OutcomeSpace of the negotiation which represent all possible agreements. In ANL 2024, this will always be of type DiscreteCartesianOutcomeSpace with a single issue.discrete_outcomes()A generator of all outcomes in the outcome space.log_info()Logs structured information for this negotiator that can be checked in the logs later (Similarily there arelog_error,log_warning,log_debug).
self.ufunA LinearAdditiveUtilityFunction representing the agent's own utility function. This object provides some helpful functionality including:self.ufun.is_better(a, b)Tests if outcomeais better thanb(useNonefor disagreement). Similarily we have,is_worse,is_not_worseandis_not_better.self.ufun.reserved_valueYour negotiator's reserved/reservation value (between 0 and 1). You can access this also asself.ufun(None).self.ufun(w)Returns the utility value of the outcomew. It is recommended to cast this value to float (i.e.float(self.ufun(w)) to support probabilistic utility functions.self.outcome_spaceThe OutcomeSpace of the negotiation which represent all possible agreements. In ANL 2024, this will always be of type DiscreteCartesianOutcomeSpace with a single issue.self.ufun.invert()Returns and caches an InverseUtilityFunction object which can be used to find outcomes given their utilities. The most important services provided by the InverseUtilityFunction returned are:minmax()returns the minimum and maximum values of the ufun (will always be (0, 1) approximately in ANL 2024).best(),worst()returns the best (worst) outcomes.one_in(),some_in()returns one (or some) outcomes within the given range of utilities.next_better(),next_worse()returns the next outcome descendingly (ascendingly) in utility value.
self.opponent_ufunA LinearAdditiveUtilityFunction representing the opponent's utility function. You can access this also asself.private_info["opponent_ufun"]. This utility function will have a zero reserved value independent of the opponent's true reserved value. You can actually set the reserved value on this object to your best estimate. All ufun funcationality is available in this object.
Other than these objects, your negotiator can access any of the analytic facilities available in NegMAS. For example, you can calculate the pareto_frontier, Nash Bargaining Soluion, Kalai Bargaining Solution, points with maximum wellfare, etc. You can check the implementation of the NashSeeker agent for examples of using these facilities.
Other than implementing the __call__, method you can optionally implement one or more of the following callbacks to initialize your agent:
on_negotiation_start(state: SAOState)This callback is called once per negotiation after the ufuns are set but before any offers are exchanged.on_preferences_changed(changes)This callback is called whenever your negotiator's ufun is changed. This will happen at the beginning of each negotiation but it can also happen again if the ufun is changed while the negotiation is running. In ANL 2024, ufuns never change during the negotiation so this callback is equivalent toon_negotiation_start()but for future proofness, you should use this callback for any initialization instead to guarantee that this initialization will be re-run in cases of changing utility function.
Understanding our negotiator
Now we can analyze the simple random negotiator we developed earlier.
- Firstly, we find the current offer that we need to respond to:
- Acceptance Strategy We then accept this offer if three conditions are satisfied:
- The offer is not
Nonewhich means that we are not starting the negotiation just now: - The offer is not worse than disagreement. This prevents us from accepting irrational outcomes.
- A random number we generated is less than 0.25. This means we accept rational offers with probability 25%.
- Offering Strategy If we decided not to accept the offer, we simply generate a single random outcome and offer it:
This negotiator did not use the fact that we know the opponent utility function up to reserved value. It did not even use the fact that we know our own utility function. As expected, it did not get a good score. Let's develop a simple yet more meaningful agent that uses both of these pieces of information.
Can you now see why is this negotiator is getting negative advantages sometimes? We were careful in our acceptance strategy but not in our offering strategy. There is nothing in our code that prevents our negotiator from offering irrational outcomes (i.e. outcomes worse than disagreement for itself) and sometimes the opponent will just accept those. Can you fix this?
A more meaningful negotiator
How can we use knowledge of our own and our opponent's utility functions (up to reserved value for them)? Here is one possibility:
- Acceptance Strategy We accept offers that have a utility above some aspiration level. This aspiration level starts very high (1.0) and goes monotoncially down but never under the reserved value which is reached when the relative time is 1.0 (i.e. by the end of the negotiation). This is implemented in
is_acceptable()below. -
Opponent Modeling We estimate the opponent reserved value under the assumption that they are using a monotonically decreasing curve to select a utility value and offer an outcome around it. This is implemented in
update_reserved_value()below. -
Bidding Strategy Once we have an estimate of their reserved value, we can then find out all outcomes that are rational for both we and them. We can then check the relative time of the negotiation and offer outcomes by conceding over this list of rational outcomes. This is implemented in the
generate_offer()method below.
from scipy.optimize import curve_fit
def aspiration_function(t, mx, rv, e):
"""A monotonically decreasing curve starting at mx (t=0) and ending at rv (t=1)"""
return (mx - rv) * (1.0 - np.power(t, e)) + rv
class SimpleRVFitter(SAONegotiator):
"""A simple curve fitting modeling agent"""
def __init__(self, *args, e: float = 5.0, **kwargs):
"""Initialization"""
super().__init__(*args, **kwargs)
self.e = e
# keeps track of times at which the opponent offers
self.opponent_times: list[float] = []
# keeps track of opponent utilities of its offers
self.opponent_utilities: list[float] = []
# keeps track of our last estimate of the opponent reserved value
self._past_oppnent_rv = 0.0
# keeps track of the rational outcome set given our estimate of the
# opponent reserved value and our knowledge of ours
self._rational: list[tuple[float, float, Outcome]] = []
def __call__(self, state):
# update the opponent reserved value in self.opponent_ufun
self.update_reserved_value(state.current_offer, state.relative_time)
# run the acceptance strategy and if the offer received is acceptable, accept it
if self.is_acceptable(state.current_offer, state.relative_time):
return SAOResponse(ResponseType.ACCEPT_OFFER, state.current_offer)
# call the offering strategy
return SAOResponse(ResponseType.REJECT_OFFER, self.generate_offer(state.relative_time))
def generate_offer(self, relative_time) -> Outcome:
# The offering strategy
# We only update our estimate of the rational list of outcomes if it is not set or
# there is a change in estimated reserved value
if (
not self._rational
or abs(self.opponent_ufun.reserved_value - self._past_oppnent_rv) > 1e-3
):
# The rational set of outcomes sorted dependingly according to our utility function
# and the opponent utility function (in that order).
self._rational = sorted(
[
(my_util, opp_util, _)
for _ in self.nmi.outcome_space.enumerate_or_sample(
levels=10, max_cardinality=100_000
)
if (my_util := float(self.ufun(_))) > self.ufun.reserved_value
and (opp_util := float(self.opponent_ufun(_)))
> self.opponent_ufun.reserved_value
],
)
# If there are no rational outcomes (e.g. our estimate of the opponent rv is very wrong),
# then just revert to offering our top offer
if not self._rational:
return self.ufun.best()
# find our aspiration level (value between 0 and 1) the higher the higher utility we require
asp = aspiration_function(relative_time, 1.0, 0.0, self.e)
# find the index of the rational outcome at the aspiration level (in the rational set of outcomes)
max_rational = len(self._rational) - 1
indx = max(0, min(max_rational, int(asp * max_rational)))
outcome = self._rational[indx][-1]
return outcome
def is_acceptable(self, offer, relative_time) -> bool:
"""The acceptance strategy"""
# If there is no offer, there is nothing to accept
if offer is None:
return False
# Find the current aspiration level
asp = aspiration_function(
relative_time, 1.0, self.ufun.reserved_value, self.e
)
# accept if the utility of the received offer is higher than
# the current aspiration
return float(self.ufun(offer)) >= asp
def update_reserved_value(self, offer, relative_time):
"""Learns the reserved value of the partner"""
if offer is None:
return
# save to the list of utilities received from the opponent and their times
self.opponent_utilities.append(float(self.opponent_ufun(offer)))
self.opponent_times.append(relative_time)
# Use curve fitting to estimate the opponent reserved value
# We assume the following:
# - The opponent is using a concession strategy with an exponent between 0.2, 5.0
# - The opponent never offers outcomes lower than their reserved value which means
# that their rv must be no higher than the worst outcome they offered for themselves.
bounds = ((0.2, 0.0), (5.0, min(self.opponent_utilities)))
try:
optimal_vals, _ = curve_fit(
lambda x, e, rv: aspiration_function(
x, self.opponent_utilities[0], rv, e
),
self.opponent_times,
self.opponent_utilities,
bounds=bounds,
)
self._past_oppnent_rv = self.opponent_ufun.reserved_value
self.opponent_ufun.reserved_value = optimal_vals[1]
except Exception as e:
pass
anl2024_tournament(
n_scenarios=1, n_repetitions=3, nologs=True, njobs=-1,
competitors=[MyRandomNegotiator, SimpleRVFitter, Boulware, Conceder]
).final_scores
Will run 48 negotiations on 1 scenarios between 4 competitors
Output()
strategy score 0 Boulware 0.648516 1 SimpleRVFitter 0.562182 2 Conceder 0.314239 3 MyRandomNegotiator 0.040486
| strategy | score | |
|---|---|---|
| 0 | Boulware | 0.648516 |
| 1 | SimpleRVFitter | 0.562182 |
| 2 | Conceder | 0.314239 |
| 3 | MyRandomNegotiator | 0.040486 |
Much better :-)
Let's see how each part of this negotiator works and how they fit together.
Construction
The first method of the negotiator to be called is the __init__ method which is called when the negotiator is created usually before the ufun is set. You can use this method to construct the negotiator setting initial values for any variables you need to run your agent.
An important thing to note here is that your negotiator must pass any parameters it does not use to its parent to make sure the object is constructed correctly. This is how we implement this in our SimpleRVFitter:
We then set the variables we need for our negotiator:
self.estores the exponent of the concession curve we will be use (more on that later).self.opponent_times,self.opponent_utilitieskeep track of the times the opponent offers and its own utility of its offers. We will use that to estimate the opponent's reserved value using simple curve fitting inupdate_reserved_values().self._past_oppnent_rv = 0.0We start assuming that the opponent has zero reserved value. This is an optimistic assumption because it means that anything rational for us is rational for the opponent so we have more negotiation power.self._rationalThis is where we will store the list of rational outcomes to concede over. For each outcome we will store our utility, opponent utility and the outcome itself (in that order).
Overall Algorithm
The overall algorithm is implemented --- as usual --- in the __call__() method. This is the complete algorithm:
def __call__(self, state):
self.update_reserved_value(state.current_offer, state.relative_time)
if self.is_acceptable(state.current_offer, state.relative_time):
return SAOResponse(ResponseType.ACCEPT_OFFER, state.current_offer)
return SAOResponse(ResponseType.REJECT_OFFER, self.generate_offer(state.relative_time))
We start by updating our estimate of the reserved value of the opponent using update_reserved_value(). We then call the acceptance strategy is_acceptable() to check whether the current offer should be accepted. If the current offer is not acceptable, we call the bidding strategy generate_offer() to generate a new offer which we return as our counter-offer. Simple!!
Opponent Modeling (Estimating Reserved Value)
The first step is in our algorithm is to update our estimate of the opponent's reserved value. This is done in three simple steps:
- If we have not offer from the opponent, there is nothing to do. Just return:
- We append the time and opponent's utility to our running list of opponent offer utilities:
-
We apply a simple curve fitting algorithm from scipy to estimate the opponent's reserved value (and its concession exponent but we are not going to use that):
- We set the bounds of the reserved value to be between zero (minimum possible value) and the minimum utility the opponent ever offered. This assumes that the opponent only offers rational outcomes for itself. The bounds for the concession curve are set to (0.2, 5.0) which is the usual range of exponents used by time-based strategies.
- We then just apply curve fitting while keeping the old estimate. We keep the old estimate to check whether there is enough change to warrent reevaluation of the rational outcome sets in our offering strategy. We ignore any errors keeping the old estimate in that case.
Note that we just passoptimal_vals, _ = curve_fit( lambda x, e, rv: aspiration_function(x, self.opponent_utilities[0], rv, e), self.opponent_times, self.opponent_utilities, bounds=bounds )self.opponent_utilities[0]as the maximum for the concession curve because we know that this is the utility of the first offer from the opponent.- Finally, we update the opponent reserved value with our new estimate keeping the latest value for later:
Acceptance Strategy
Our acceptance strategy is implemented in is_acceptable() and consists of the following steps:
- Reject if no offer is found (i.e. we are starting the negotiation now):
- Find our current aspiration level which starts at 1.0 (inidicating we will only accept our best offer in the first step) ending at our reserved value (indicating that we are willing to accept any rational outcome by the end of the negotiation). Use the exponent we stored during construction.
- Accept the offer iff its utility is higher than the aspiration level: Note that this acceptance strategy does not use the estimated opponent reserved value (or the opponent's ufun) in any way.
Bidding Strategy
Now that we have updated our estimate of the opponent reserved value and decided not to accept their offer, we have to generate our own offer which the job of the bidding strategy implementedin generate_offer(). This is done in three steps as well:
-
If the difference between the current and last estimate of the opponent reserved value is large enough, we create the rational outcome list.
- This test is implemented by:
- We then create of all outcomes prepending them with our and opponent's utility values:
- Finally, we sort this list. Because each element is a tuple, the list will be sorted ascendingly by our utility with equal values sorted ascendingly by the opponent utility.
-
If there are no rational outcomes (e.g. our estimate of the opponent rv is very wrong), then just revert to offering our top offer
- If we have a rational set, we calculate an aspiration level that starts at 1 and ends at 0 (note that we do not need to end at the reserved value because all outcomes in
self._rationalare already no worse than disagreement. We then calculate the outcome that is at the current aspiration level from the end of the rational outcome list and offer it:
Running a single negotiation
What if we now want to see what happens in a single negotiation using our shiny new negotiator? We first need a scenario to define the outcome space and ufuns. We can then add negotiators to it and run it. Let's see an example:
import copy
from negmas.sao import SAOMechanism
from anl.anl2024.runner import mixed_scenarios
from anl.anl2024.negotiators.builtins import Linear
# create a scenario
s = mixed_scenarios(1)[0]
# copy ufuns and set rv to 0 in the copies
ufuns0 = [copy.deepcopy(u) for u in s.ufuns]
for u in ufuns0:
u.reserved_value = 0.0
# create the negotiation mechanism
session = SAOMechanism(n_steps=1000, outcome_space=s.outcome_space)
# add negotiators. Remember to pass the opponent_ufun in private_info
session.add(
SimpleRVFitter(name="SimpleRVFitter",
private_info=dict(opponent_ufun=ufuns0[1]))
, ufun=s.ufuns[0]
)
session.add(Linear(name="Linear"), ufun=s.ufuns[1])
# run the negotiation and plot the results
session.run()
session.plot()
plt.show()
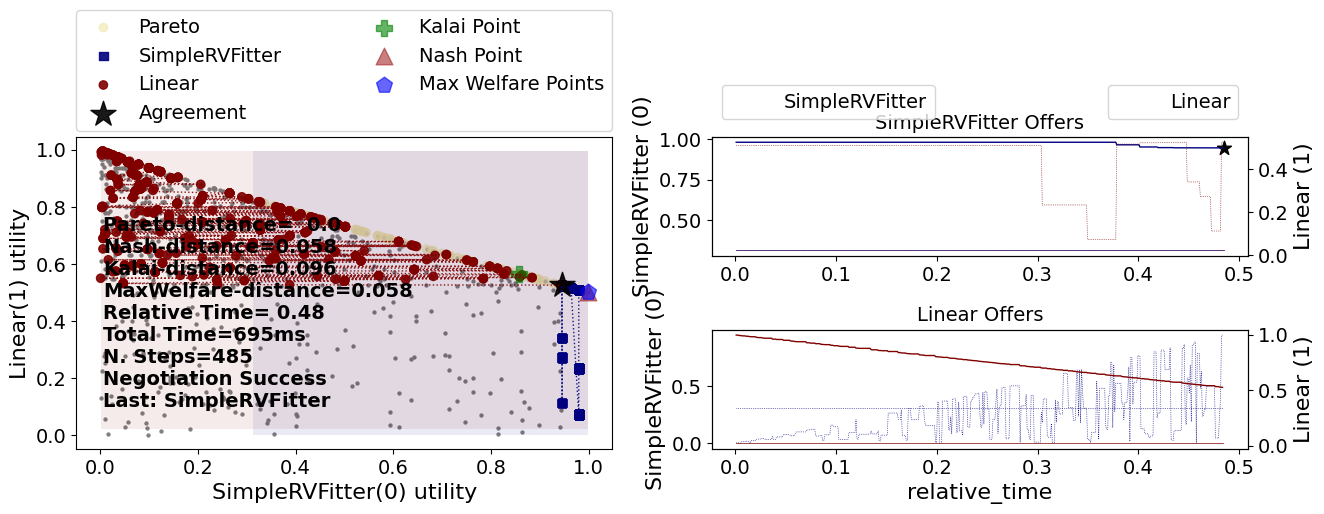
Notice how in the second half of the negotiation, the SimpleRVFitter is only offering outcomes that are rational for both negotiators (can you see that in the left-side plot? can you see it in the top right-side plot?). This means that the curve fitting approach is working OK here. The opponent is a time-based strategy in this case though.
What happens if it was not? Let's try it against the builtin RVFitter for example
from anl.anl2024.negotiators import RVFitter
# create the negotiation mechanism
session = SAOMechanism(n_steps=1000, outcome_space=s.outcome_space)
# add negotiators. Remember to pass the opponent_ufun in private_info
session.add(
SimpleRVFitter(name="SimpleRVFitter",
private_info=dict(opponent_ufun=ufuns0[1]))
, ufun=s.ufuns[0]
)
session.add(
RVFitter(name="RVFitter",
private_info=dict(opponent_ufun=ufuns0[0]))
, ufun=s.ufuns[1]
)
# run the negotiation and plot the results
session.run()
session.plot()
plt.show()
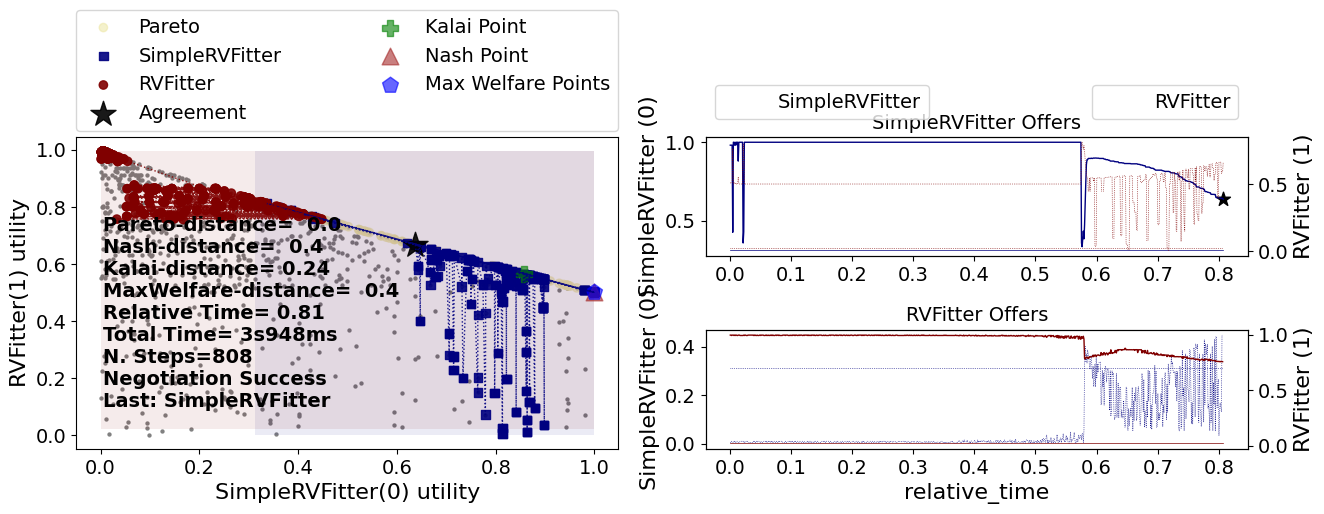
This time, our simple RV fitter could not really learn the opponent reserved value effectively. We can see that from the fact that it kept offering outcomes that are irrational for the opponent almost until the end of the negotiation.
The builtin RVFitter seems better in this case. It took longer but it seems to only offer rational outcomes for its opponent (our SimpleRVFitter) after around 60% of the available negotiation time.
Other Examples
The ANL package comes with some example negotiators. These are not designed to be stong but to showcase how to use some of the features provided by the platform.
- MiCRO A strong baseline behavioral negotiation strategy developed by de Jonge, Dave in "An Analysis of the Linear Bilateral ANAC Domains Using the MiCRO Benchmark Strategy.", ICJAI 2022. This strategy assumes no knowledge of the opponent utility function and is implemented from scratch to showcase the following:
- Using
on_preferences_changedfor initialization. - Using PresortingInverseUtilityFunction for inverting a utility function.
- Using
- NashSeeker A naive strategy that simply sets the opponent reserved value to a fixed value and then uses helpers from NegMAS to find the Nash Bargaining Solution and use it for deciding what to offer. This showcases:
- Using NegMAS helpers to calculate the pareto-frontier and the Nash Bargaining Solution
- RVFitter A strategy very similar to the one we implemented earlier as
SimpleRVFitter. Instead of trying to estiamte the opponent reserved value from the first step, this strategy waits until it collects few offers before attempting the etimation. This showcases:- Setting the opponent reserved value based on our best estimate.
- A simple way to use this estimate for our bidding strategy.
- Using logging. Logs can be saved using
self.nmi.log_info(dict(my_key=my_value))and found under the logs folder.
- Boulware, Conceder, Linear Time-based strategies that are implemented by just setting construction parameters of an existing NegMAS negotiator
- StochasticBoulware, StochasticConceder, StochasticLinear Stochastic versions of the three time-based strategies above implemented by just setting construction parameters of an existing NegMAS negotiator
- NaiveTitForTat A simple behavioral strategy implemented by just inheriting from an existing NegMAS negotiator.
Note about running tournaments
- When running a tournament using
anl2024_tournamentinside a Jupyter Notebook, you must passnjobs=-1to force serial execution of negotiations. This is required because the multiprocessing library used by NegMAS does not play nicely with Jupyter Notebooks. If you run the tournament using the same method from a.pypython script file, you can omit this argument to run a tournament using all available cores. - When you pass
nologs=True, no logs are stored for this tournament. If you omit this argument, a log will be created under~/negmas/anl2024/tournamentswhich can be visualized using the ANL visualizer by running: